The CHaMP Workbench can scrape the results of the topo validation AWS worker engine and store them in the workbench database for further processing. The goal is to provide the contents of the topo validation logs in a format that supports easy querying and filtering.
What is the Topo Validation Worker Engine
The Topo Validation worker engine is a Python script that looks at the content of a CHaMP Topo Toolbar project and tests its correctness using over 100 or so validation checks. It checks for missing layers, problematic geometries, tabular attributes etc.
This python script is automated on Amazon AWS and run periodically by operators. The output is a log file that summarizes the status of every test into pass/fail/warning, as well as as an over all status for the entire validation process.
How to Scrape Validation Results
-
Ensure that you’ve run topo validation for the desired set of visits and that you’ve provided sufficient time for the validation to complete for all visits. You can use AWS SQS and Cloudwatch to monitor progress of the topo validation worker engine.
- Use the AWS CLI to download topo validation log files from S3 to your local computer. Note that you want the XML version of the topo validation log, not the plain text version that ends with
.log. The typical command is:aws s3 sync s3://champdata-sfr/QA D:\MyLocalPath\ValidationLogs --exclude * --include 'validation.xml' -
Open the CHaMP Workbench Software.
-
Click on Scrape Validation Log XML Files… from the Experimental menu under Philip
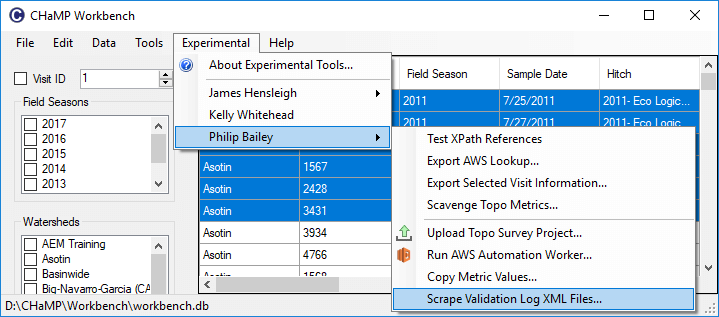
-
You will be asked if you want to delete existing validation log records. If you’re unsure then close the workbench and backup your database before proceeding. It’s simplest if you only maintain one set of validation logs in each workbench database at a time.
-
Next you will be prompted to browse to the top level folder that contains the log files. i.e. browse to the local folder that you used in the AWS sync in the previous step. This is just the top level folder considered. The scraper works recursively through all sub folders of this top level folder.
- When you click OK to select the folder, the scraper will run and report the total number of files scraped into the workbench database.
Where are Validation Results Stored
The topo validation log XML files are parsed and stored in two tables in the workbench database:
-
The LogFiles table stores one record for each topo validation log file scraped. The fields are:
- LogID - auto incrementing ID assigned to each topo validation log file.
- Status - Plain english word representing either
pass,error,warningfor the overall topo validation process. - LogFilePath - the full, absolute path of the log file that was scraped.
- VisitID - the official CHaMP Visit ID for the visit that was processed for this log.
- DateRun - the date and time that the topo validation was performed.
- DateScavenged - the date and time that the topo validation was scraped into the workbench database.
- ResultFilePath - not used
- MetaDataInfo - not used
- BatchRunID - not used
- ResultID - not used.
-
The LogMessages table stores one record for each entry in the topo validation log file. Typically there are dozens of messages per topo validation run. The fields are:
- LogMessageID - auto incrementing ID assigned to each topo validation log message.
- LogID - the parent ID in LogFiles of the log record that this message belongs to.
- TargetVisitID - the official CHaMP Visit ID for the visit that was processed for this log.
- SourceVisitID - same as TargetVisitID
- MessageType - plain english text describing the status of the particular test being performed. Either
Error,Pass,Not TestedorWarning. - LogSeverity - not used
- LogDateTime - not used
- LogMessage - the contents of the topo validation log message.
- LogException - not used
- LogSolution - this is used to store the name of the layer being processed when the message was generated. (i.e. this solution field is being used for this purpose and the contents doesn’t really represent a solution.)