The Workbench is capable of triggering worker engines that automate various CHaMP processes. These engines run on Amazon Web Services (AWS), but the Workbench can be used to launch them for a selection of visits.
Running a single worker engine for a single visit creates one entry in a queue on AWS. Jobs arriving in a queue trigger one or more virtual computers to be launched which then process the items in the queue. Processing an item removes it from the queue and once all items have been processed and the queue is empty, the virtual computers are shut down. The number of virtual computers depends on the number of items in the queue and there can be as many as 80 virtual computers running at any time.
The high level sequence of steps that occurs once an item arrives in a queue are as follows:
- Determine what type of worker engine is required.
- Retrieve the necessary inputs for the worker engine and place them on AWS S3.
- Launch a virtual computer.
- Retrieve the latest source code for the worker engine and place it on the virtual computer
- Run the worker engine.
- Retrieve the worker engine outputs and log files and:
- Zip the relevant outputs and upload them to CHaMP Monitoring
- Insert the relevant metrics into metrics schemas on CHaMP Monitoring.
- Retain the log files on AWS S3 should they be required for troubleshooting.
Since different worker engines require a different length of time to complete, there are separate queues for short and long running items. Technically you can place any type of worker engine in any queue, but you should read the documentation below for the best practices.
Available Worker Engines
Worker engines are small, standalone Python scripts that perform a single task or operation. The existing engines are:
- Topo Metrics - Calculate and report a set of measurements from a series of GIS layers.
- Hydro Prep - Export a DEM, water surface DEM and Thalweg GIS layers to CSV text files. These three text files then form the main input to running the Delft3D hydraulic model.
- Site Props - Summarize all visits to a site. This project performs the followingoperations:
- Intersects the visit survey extents to a site and writes them to a ShapeFile.
- Unions the visit survey extents to a site and writes them to a ShapeFile.
- Concatenates the control networks for all visits to a new ShapeFile.
- Writes an XML file that summarizes various properties of each visit.
- Topo Validation - Runs a series of validation checks against the GIS layers generated from a topographic survey and writes a report summarizing the results.
How to Run a Worker Engine
- Download and install the latest CHaMP Workbench. Check for updates if you haven’t done so in a while.
- Open the Workbench.
- Ensure that the visits that you want to run are present in the Workbench database. If you’re unsure then synchronize your CHaMP Data before proceeding.
- Select the visits for which you want the worker engine in the main Workbench grid. Use the filter controls on the left to narrow the displayed visits and then use the
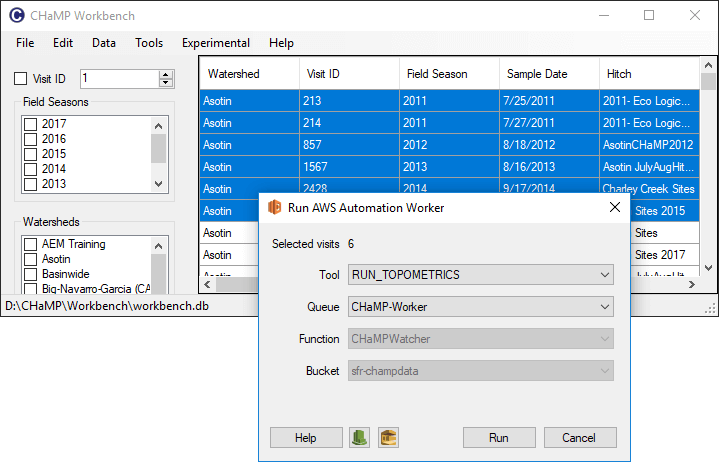
ShiftandCTRLkeys to select continuous or discontinuous sets of visits, respectively. - Choose Run AWS Automation Worker from the Experimental menu under Philip.
- Confirm that the desired number of visits appears at the top of the form that appears.
- Pick the worker engine that you want to run next to where it says Tool. See the available worker engines list above.
- Pick the queue that you want to use. Choose the
CHaMP-LongRunfor running Delft 3D hydraulic model. For all other worker engines chooseCHaMP-Worker. Do not use theQA-CHaMP-Workerqueue without consulting North Arrow Research. - The Function and Bucket inputs are read only and can be ignored.
- Before you click the Run button, it can be useful to click both the green Cloud Watch and yellow SQS buttons near the bottom of the form. These will open the respective AWS tools so that you can monitor the progress of the worker engines that you are about to launch.
- Click the Run button to launch the worker engines.
Notes
- If a worker engine produces metrics then any existing metric values will be removed as part of uploading new metrics when a worker engine finishes.